
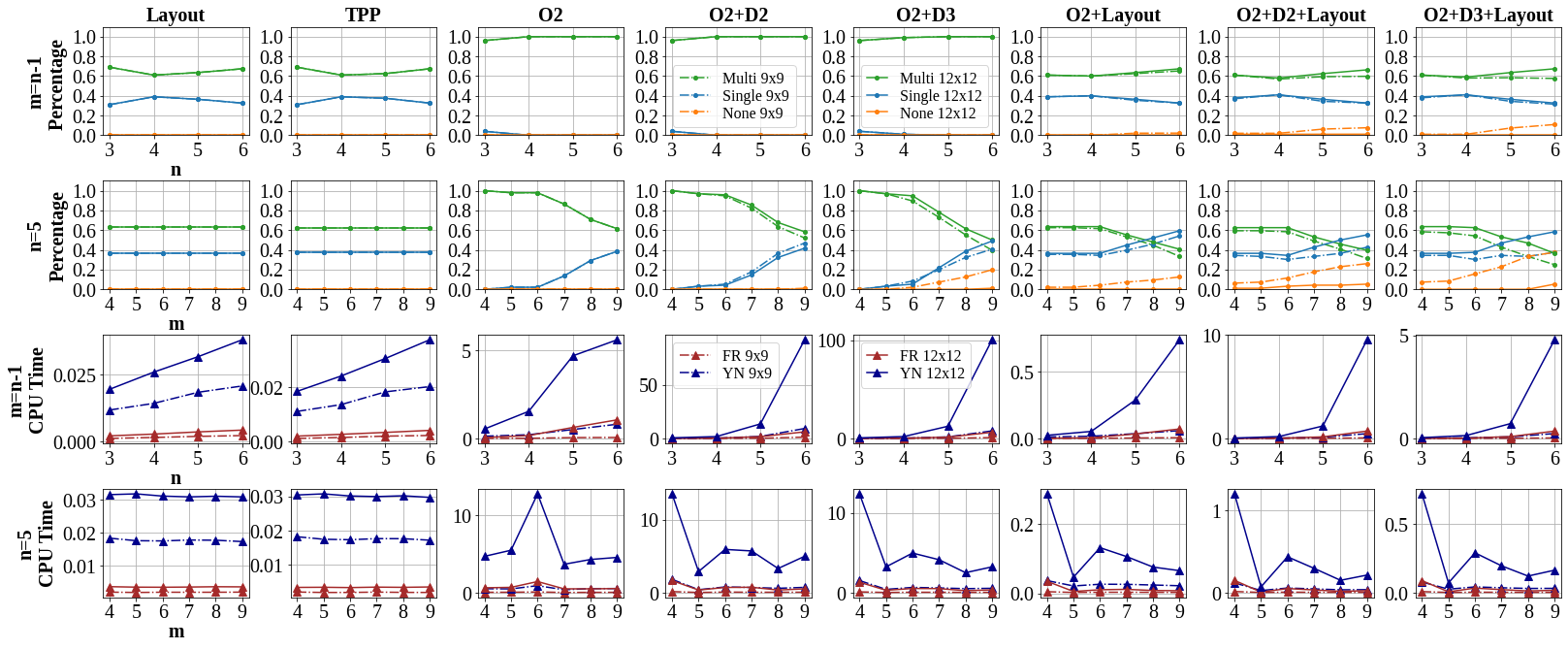
We evaluate various GPT models. Our evaluation is conducted under a zero-shot setting to assess the capability of models to generate accurate answers without fine-tuning or few-shot demonstrations on our benchmark. For all models, we use the story and question directly for Yes/No QA.
Human Expert
Open-Source
Proprietary
| Reset | n=3 | n=4 | n=5 | n=6 |
| Azure GPT-4* | 0.56 | 0.34 | 0.21 | 0.16 |
| Azure GPT-3.5-Turbo* | 0.47 | 0.15 | 0.05 | 0.0 |
| Azure GPT-3 Dalle* | 0.46 | 0.25 | 0.08 | 0.09 |
Overall results of different models on the RoomSpace test set. The best-performing model in each category is in-bold, and the second best is underlined. *: results provided by the authors.